 Maximally Entangled
Maximally Entangled
August 7, 2008
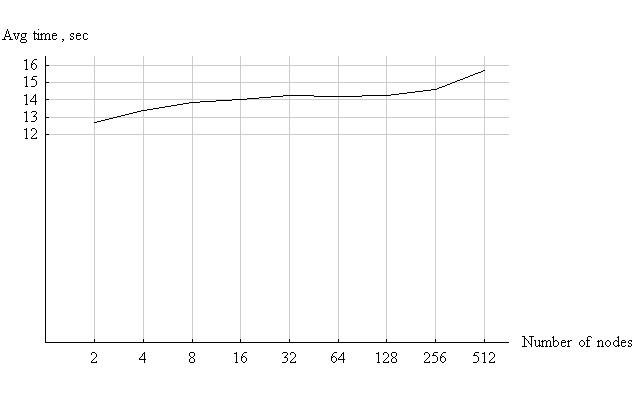 Pretty interesting graph eh? I am a big Werner Vogels fan, and it is nice to see that he definitely practices what he preaches when it comes to distributed computing principles & constraints. The graph is for an Amazon EC2 grid being scaled and provisioned upto 512 nodes using GridGain, JVM5, Fedora 8 & OpenMQ. It is pretty impressive to see the completion time for a job remain relatively linear from 8 nodes to 256. Even after it hits 512 nodes, the overall degradation remains <20%. As anybody in the know would tell you - scalability & performance are not the same thing. Scalability is a point on the price-performance curve. Performance is the ultimate throughput a single node can give you. Depending on the Consistency, Availability & Partition
Tolerance (CAP) requirements of your solution - the price & performance will vary significantly. One thing that Max didn’t cover in his very useful analysis of EC2 was how one could leverage the “command & control” (C&C) console he built that coupled EC2 availability with Grid activity for versioning & updates. He tantalizes me by mentioning grid autonomy & the ability to provision the grid dynamically based on load. But what about using that same console to manage the gradual roll-out of updates. Based on the load, the C&C could decide to roll-out a new image/version of the application slowly or quickly.
Pretty interesting graph eh? I am a big Werner Vogels fan, and it is nice to see that he definitely practices what he preaches when it comes to distributed computing principles & constraints. The graph is for an Amazon EC2 grid being scaled and provisioned upto 512 nodes using GridGain, JVM5, Fedora 8 & OpenMQ. It is pretty impressive to see the completion time for a job remain relatively linear from 8 nodes to 256. Even after it hits 512 nodes, the overall degradation remains <20%. As anybody in the know would tell you - scalability & performance are not the same thing. Scalability is a point on the price-performance curve. Performance is the ultimate throughput a single node can give you. Depending on the Consistency, Availability & Partition
Tolerance (CAP) requirements of your solution - the price & performance will vary significantly. One thing that Max didn’t cover in his very useful analysis of EC2 was how one could leverage the “command & control” (C&C) console he built that coupled EC2 availability with Grid activity for versioning & updates. He tantalizes me by mentioning grid autonomy & the ability to provision the grid dynamically based on load. But what about using that same console to manage the gradual roll-out of updates. Based on the load, the C&C could decide to roll-out a new image/version of the application slowly or quickly.
General Architecture: 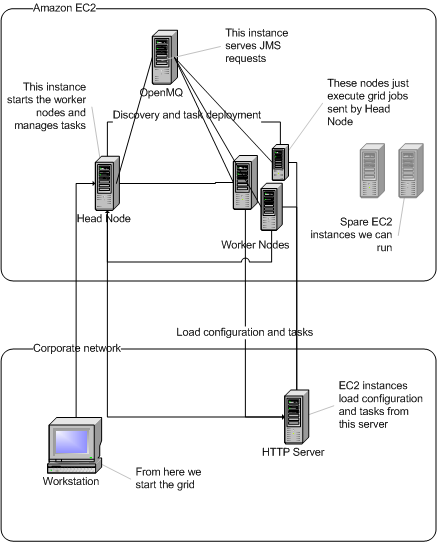
It was also very nice to see the custom image support working well, it seemed like a pretty smooth experience for the Max & GridGain. I am a little skeptical on ActiveMQ & OpenMQ being blamed for any & all scalability issues that were encountered during this test. But I’ll take that on face value for now. it would be interesting to see how RabbitMQ would fare as well. However, I am not sure if AMQP is a valid Service Provider Interface (SPI) in the GridGain world. Keep up the good work Max!
Previous post Online Process Modeling - state of the union A lot of deserved attention goes to Lombardi’s Blueprint tool for innovating with GWT and bringing collaborative process modeling and sharing to the Next post Prediction - Olympics Mumbai 2036 So, with all the hoopla around making Cricket an Olympic sport by 2020 (Twenty20 in 2020, get it?) I figured we could concieve of a theoretical